This week is completely an introduction to a new concept in C, very different from the previous week’s lecture.
The week talks more on Data Structure, I learned about Linked list, Hash table, a combination of array and linked list, also some basic introduction to Tries, Stack, and Queue.
My Summary
Data structures are programming constructs that allow us to store information in different layouts in our computer’s memory.
- To build a data structure, we will need an understanding of
- Struct to create custom data types
- (.) to access properties in a structure
- A dereference operator * to go to an address in memory pointed to by a pointer
In the previous lecture, we have learned about some kind of data structure for representing the collection of like values
- a Struct, recall, which gives us “containers” for holding variables of different data types.
- an Array is also great for the collection of similar elements, we can do an array of integers, character, and so on, making us store data on memory contiguously, but we’ve got some problems with inserting elements, deleting elements.
- Through the use of a collection of pointers, dynamic memory allocation, and structs, we can develop a better data structure such as a Linked list, which may help us solve the problem.
Linked list
A linked list is the collection of pointers, dynamic memory allocation, and Structs, we can develop to make a better data structure that can make us shrink or grow a collection of like values to fit our need
- A Linked list node is a special kind of struct with two members:
- Data of some data types [int, char, float, and so on]
- And a pointer to another node of the same type
While linked list may require some background like structs, pointer, and dynamic memory allocation understanding, they are still some number of operation we need to understand:
- Creating a linked list when it doesn’t already exist.
- Searching through a linked list to find elements
- Inserting a new node into the linked list
- Deleting a single element from a linked list
- Deleting an entire linked list
Hash Table
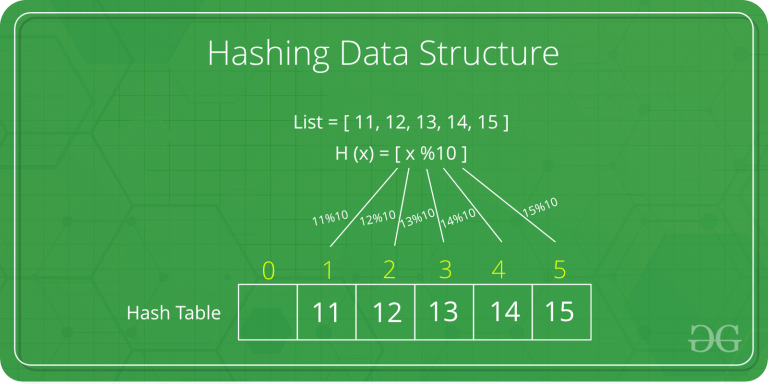
Hash Table: It combines the random access ability of an array with the dynamism of a linked list, a structure that can map keys to values. A hash table uses
- A hash function which returns a non-negative integer value called a Hash code
- an Array capable of storing data of the type we wish to place into the data structure
- A Collision occurs when two pieces of data yield the same hash code.
- Chaining and Linear probing is a technique used for avoiding collision,
Linear probing is a way of storing the item in the next empty place in the array following the occupied place. While linear probing can help reduce the collision, it can still cause a problem called clustering, where two adjacent cells will contain data
In the Chaining technique, the hash table is an array of a linked list, in which each index has its linked list. All key-value pairs mapping to the same index will be stored in the linked list of that index
/**********A simple program to show hashtable example *******/
#include <stdio.h>
#include <string.h>
#include <cs50.h>
#define MAX 10;
unsigned int hash(const char *key);
int main(void)
{
char input[10];
printf("What is your value: ");
scanf("%s", input);
int index = hash(input);
printf("%d", index);
}
//Hash function
unsigned int hash(const char *key)
{
unsigned long int value = 0;
unsigned int i = 0;
unsigned int key_len = strlen(key);
for (; i < key_len; i++)
{
value = value * 37 + key[i];
}
value = value % MAX;
return value;
}Tries
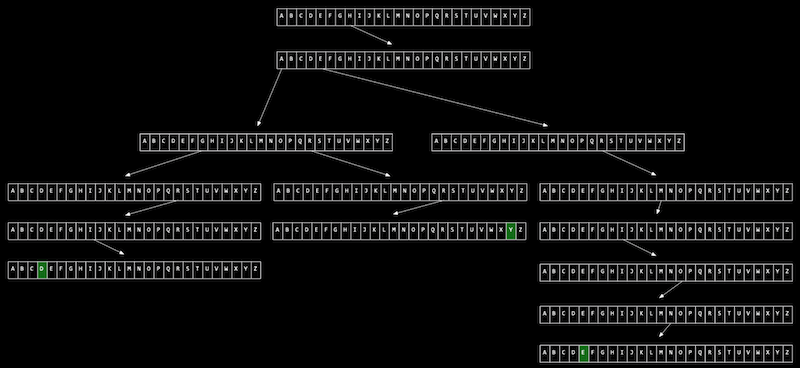
In computer science, a Trie, also called digital tree or prefix tree, is a kind of search tree -an ordered tree data structure used to store a dynamic set or associative array where the keys are usually.
Tries combine structures and pointers to store data interestingly. The data to be searched for in a Trie is the roadmap.
Unlike with hashtable, there are no collisions, and no two pieces of data (unless they are identical) have the same path.
Stack and Queue
Both are higher-level constructs, abstract data structures, where we can use our building blocks of arrays, linked lists, hash tables, and tries to implement a solution to some problem.
- Stack – Where we want to be able to add values and remove values in a first-in-first-out (FIFO) way
- Queue – Where items most recently added (pushed) are removed (popped) first, in a last-in-first-out (LIFO) way
Conclusion
While this post is just a summary of what I learned from Cs50 week 5 lecture, it may not include an in-depth explanation of the Lecture. To learn more about the course, I will urge you to consider taking the course.
If you’ve taken this course, how was your Week 5 Lecture? pls kindly comment below…
Thanks for reading…